

| Των Σωτηρίου Μπερσίμη & Χρήστου Μπουντούλη* |
Οι αλγόριθμοι μηχανικής μάθησης αποτελούν ένα εξαιρετικό εργαλείο πρόβλεψης και στοχεύουν στην ανίχνευση και μοντελοποίηση σχέσεων και μοτίβων, σε όλα τα επίπεδα της ανάλυσης. Επομένως, η αυτοματοποίηση της πρόβλεψης των ασφαλιστικών απαιτήσεων, αντικαθιστώντας τα παραδοσιακά μοντέλα με νέες, πιο σύγχρονες και πιο ακριβείς μεθόδους, δίνει την ευκαιρία στις ασφαλιστικές εταιρείες να πραγματοποιήσουν με μεγαλύτερη ακρίβεια την προετοιμασία των ετήσιων προϋπολογισμών, καθώς και να βελτιστοποιήσουν τα νέα προϊόντα τους. Με αυτόν τον τρόπο, οι ασφαλιστικές εταιρείες που εφαρμόζουν μεθόδους στατιστικής μηχανικής μάθησης και τεχνητής νοημοσύνης μπορούν να τιμολογούν στις πλέον ανταγωνιστικές τιμές, βελτιστοποιώντας το περιθώριο κέρδους τους και παραμένοντας ένα βήμα μπροστά από τον ανταγωνισμό.
Η ανάλυση αφορά αρχείο αιτήσεων αποζημίωσης για συμβόλαια ασφάλισης υγείας ιδιωτικής ασφαλιστικής εταιρείας των ΗΠΑ (η πηγή είναι γνωστό αποθετήριο δεδομένων στο διαδίκτυο). Το αρχείο εμπεριέχει δεδομένα από 1.340 αιτήσεις αποζημίωσης προς μία ασφαλιστική εταιρεία, που πραγματοποιήθηκαν εντός ενός ημερολογιακού έτους. Στο αρχείο δεδομένων, για καθεμία αίτηση αποζημίωσης εμπεριέχονται δεδομένα για τα χαρακτηριστικά τόσο του συμβάντος, όσο και του ίδιου του ασφαλισμένου. Μεταξύ των άλλων, για κάθε απαίτηση στο σύνολο δεδομένων είναι διαθέσιμα στοιχεία όπως: ο μοναδικός κωδικός ασφαλισμένου, η ηλικία του ασφαλισμένου, το φύλο του, ο δείκτης μάζας σώματος (ΔΜΣ), η τελευταία μέτρηση αρτηριακής πίεσης πριν το συμβάν που οδήγησε στο αίτημα αποζημίωσης, εάν ο ασφαλισμένος πάσχει από διαβήτη, η οικογενειακή του κατάσταση και ο αριθμός τέκνων, εάν ο ασφαλισμένος καπνίζει, η περιοχή διαμονής του, το ύψος των ασφαλιστικών απαιτήσεων, κ.ά.
Σκοπός της ανάλυσης είναι, αρχικά, η διερεύνηση των δεδομένων, η οπτικοποίησή τους και, στη συνέχεια, η διαμόρφωση κατάλληλου μοντέλου, αξιοποιώντας τη χρήση τεχνικών και μεθόδων στατιστικής μηχανικής μάθησης, βάσει των διαθέσιμων ιστορικών δεδομένων, ούτως ώστε μελλοντικά το μοντέλο αυτό να προβλέπει αυτόματα και με ακρίβεια το ύψος των ασφαλιστικών απαιτήσεων.
Από το σύνολο των 1.340 ασφαλισμένων, το 50,6% (Ν=678) είναι άντρες και το υπόλοιπο 49,4% (Ν=662) είναι γυναίκες, με τη μέση ηλικία των ασφαλισμένων να είναι ίση με 38 έτη. Όσον αφορά την περιοχή κατοικίας τους στις ΗΠΑ, ποσοστό 26,1% (Ν=349) διαμένει στις βορειοανατολικές πολιτείες, ποσοστό 17,3% (Ν=231) στις βορειοδυτικές, ποσοστό 23,5% (Ν=314) στις νοτιοανατολικές και, τέλος, ποσοστό 33,1% (Ν=443) διαμένει στις νοτιοδυτικές πολιτείες των ΗΠΑ. Επίσης, το 43% (Ν=576) των ασφαλισμένων δεν έχει κανένα παιδί στην οικογένειά του, το 53,8% (Ν=721) έχει από 1 μέχρι 3 παιδιά και το υπόλοιπο 3,2% (Ν=43) έχει από 4 έως 5 παιδιά. Αναφορικά με τα δεδομένα που σχετίζονται με την κατάσταση της υγείας των ασφαλισμένων, παρατηρείται ότι η πλειοψηφία των ασφαλισμένων δεν είναι καπνιστές, με ποσοστό 79,6% (Ν=1066), ενώ μόλις το 20,4% (274) είναι καπνιστές. Επιπλέον, ο μέσος δείκτης μάζας σώματος των ασφαλισμένων είναι ίσος με 30,67, κάτι που δηλώνει ότι η μέση αναλογία βάρους και ύψους είναι πολύ πάνω από τα φυσιολογικά επίπεδα, όπως αυτά ορίζονται από την επιστημονική κοινότητα, ενώ αξιοσημείωτο είναι ότι το 47,9% (Ν=642) των ασφαλισμένων έχουν διαβήτη.
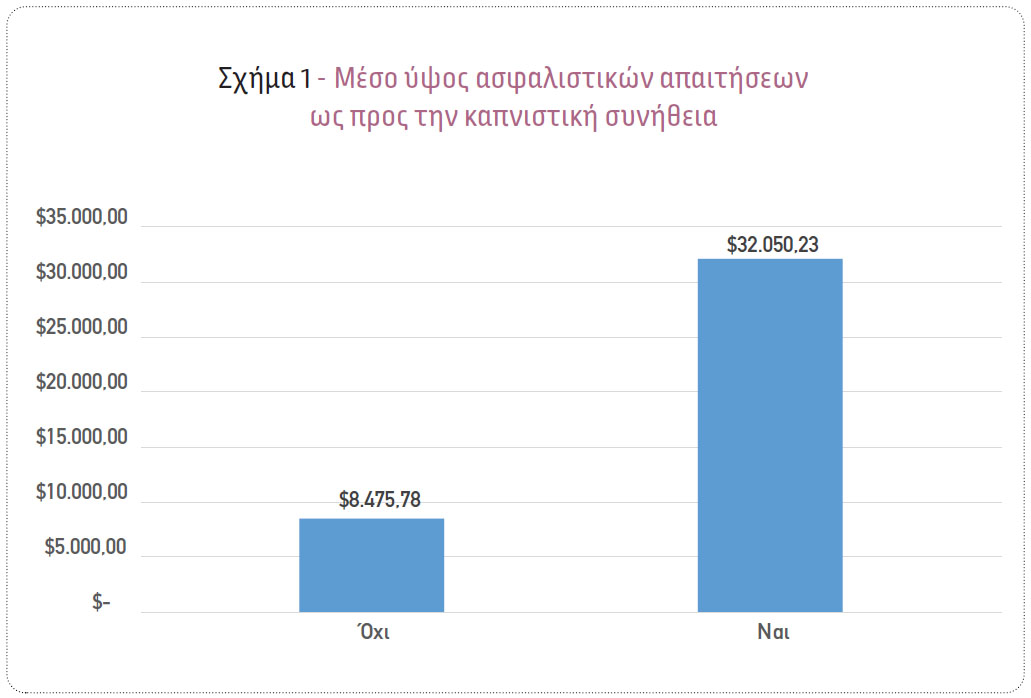
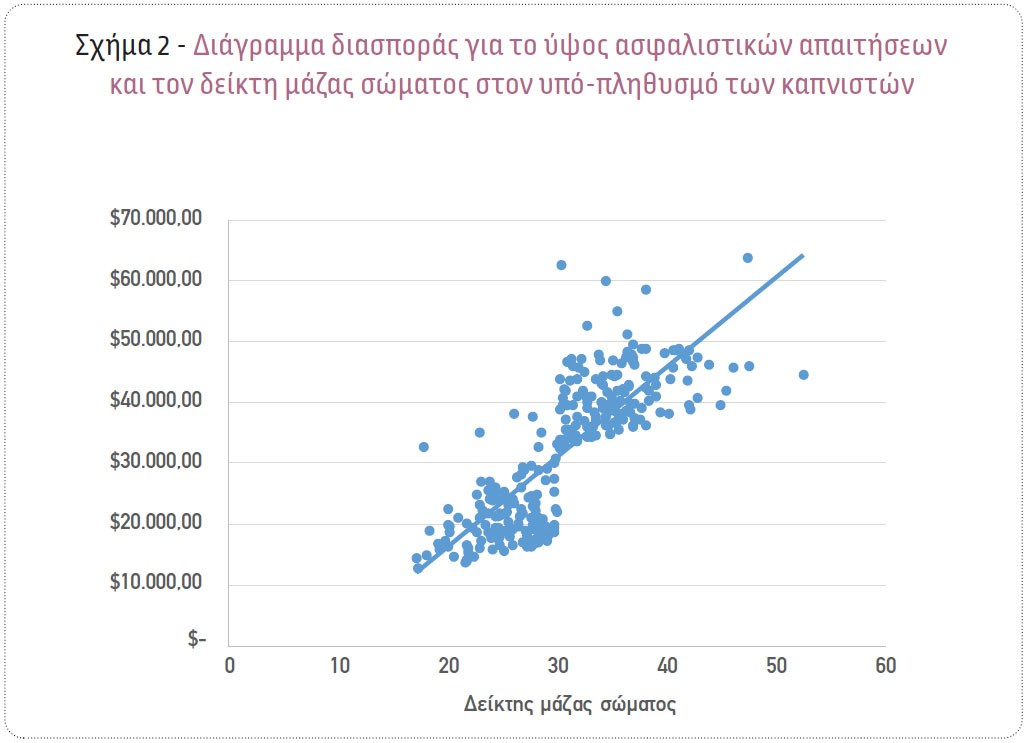
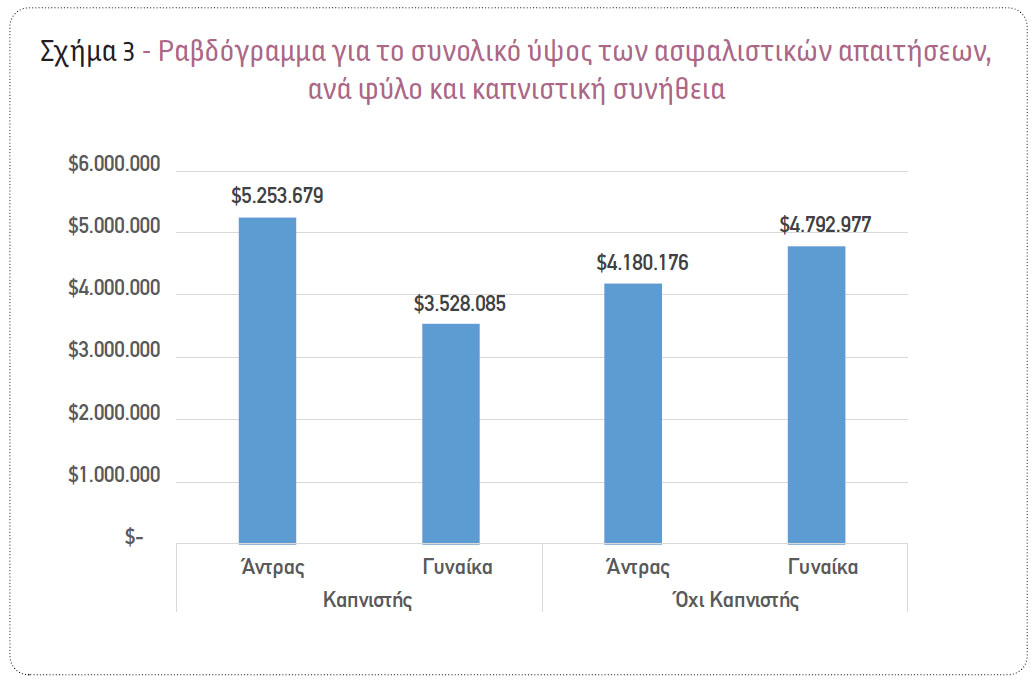
Αναλύοντας τα δεδομένα με τη χρήση κατάλληλων στατιστικών τεχνικών, προέκυψε ότι υπάρχει σημαντική διαφοροποίηση στο ύψος των αιτημάτων αποζημίωσης ανάμεσα στα αιτήματα που προέκυψαν από καπνιστές και μη καπνιστές. Συγκεκριμένα, παρατηρήθηκε ότι το μέσο ύψος ασφαλιστικών απαιτήσεων για τους μη καπνιστές είναι ίσο με $8.475,78, ενώ για τους καπνιστές είναι προσεγγιστικά 4 φορές υψηλότερο και ίσο με $32.050,23 (Σχήμα 1). Επίσης, παρατηρήθηκε ότι στην περίπτωση των καπνιστών υπάρχει μια υψηλή θετική συσχέτιση του δείκτη μάζας σώματος με το ύψος των ασφαλιστικών απαιτήσεων. Συγκεκριμένα, όσο αυξάνεται ο δείκτης μάζας σώματος, το ύψος των ασφαλιστικών απαιτήσεων έχει μια ισχυρή τάση προς αύξηση (Σχήμα 2). Επιπλέον, παρατηρήθηκε ότι στον πληθυσμό των καπνιστών το συνολικό ύψος των ασφαλιστικών απαιτήσεων για τους άνδρες είναι ίσο με $5.253.679, σχεδόν 48% υψηλότερο από το αντίστοιχο των γυναικών ($3.528.085). Αντιθέτως, στον πληθυσμό των μη καπνιστών, το συνολικό ύψος των ασφαλιστικών απαιτήσεων για τους άνδρες είναι ίσο με $4.180.176, σχεδόν 15% χαμηλότερο από το αντίστοιχο των γυναικών ($4.792.977) (Σχήμα 3).
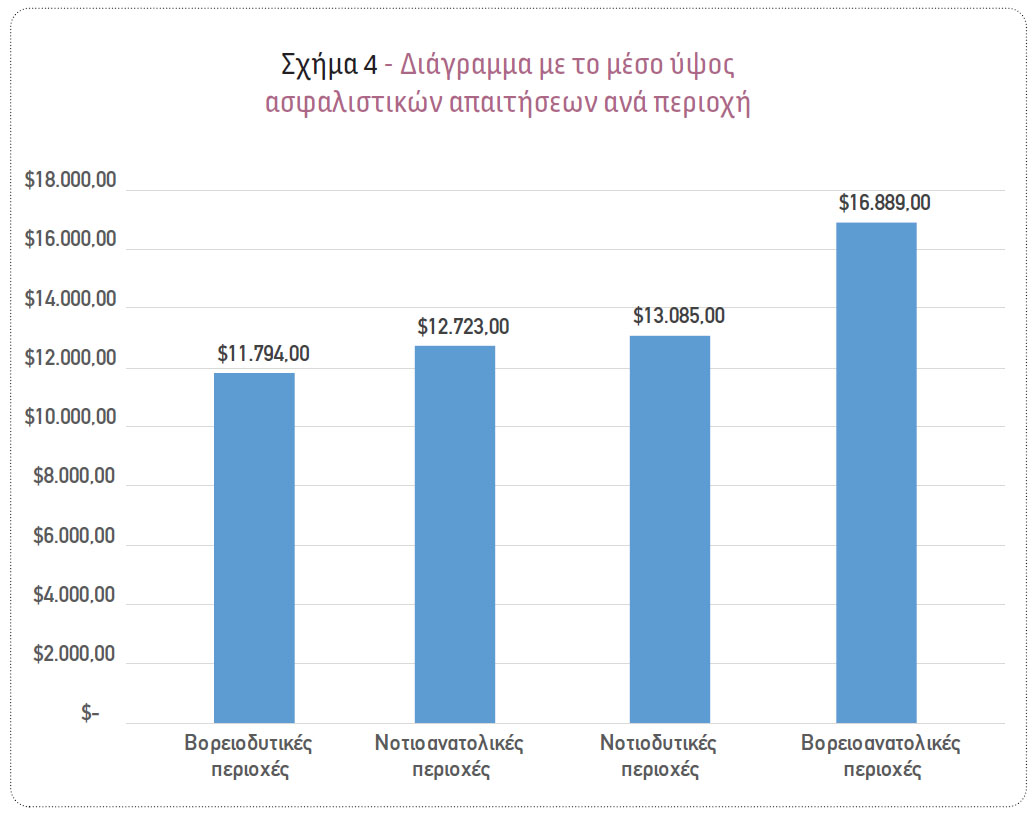
Επιπλέον, παρατηρήθηκε στατιστικά σημαντική διαφοροποίηση του ύψους των ασφαλιστικών απαιτήσεων, σε σχέση με την περιοχή διαμονής των αιτούντων αποζημίωσης ασφαλισμένων.
Συγκεκριμένα, το μέσο ύψος των ασφαλιστικών απαιτήσεων για τις νοτιοανατολικές περιοχές των ΗΠΑ είναι ίσο με $12.723, για τις νοτιοδυτικές περιοχές είναι ίσο με $13.085, για τις βορειοδυτικές περιοχές είναι ίσο με $11.794, ενώ για τις βορειοανατολικές περιοχές των ΗΠΑ είναι αρκετά υψηλότερο και ίσο με $16.889 (Σχήμα 4).
Συγκεντρώνοντας τα ευρήματα με τις διαφοροποιήσεις που προέκυψαν, μπορούμε να καθοδηγηθούμε στην κατασκευή ενός μοντέλου, το οποίο θα λειτουργεί ως μηχανισμός πρόβλεψης του ύψους των μελλοντικών ασφαλιστικών απαιτήσεων.
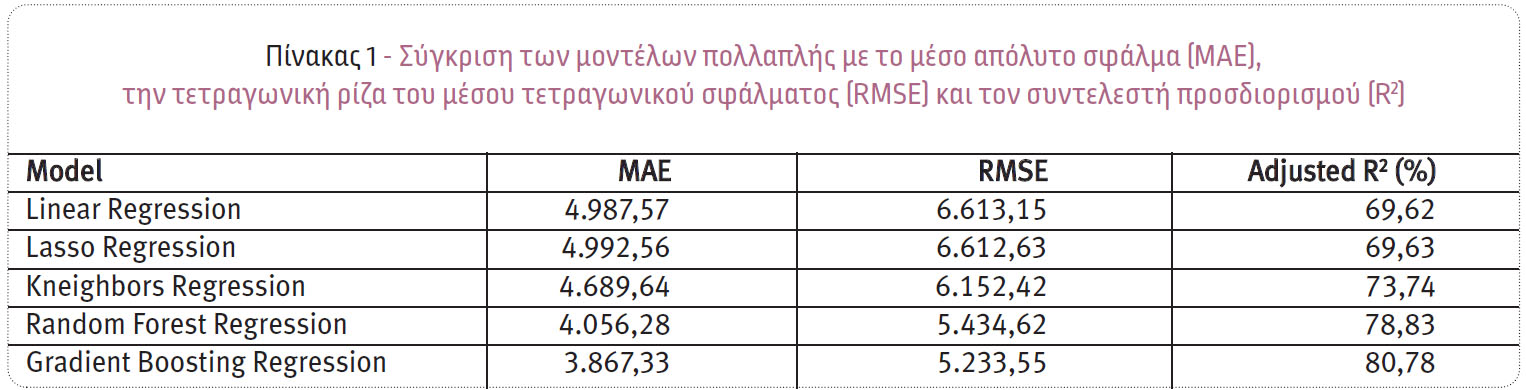
Η ανάλυση θα στηριχθεί σε προηγμένες τεχνικές της Ανάλυσης Παλινδρόμησης (Regression Analysis), η οποία σήμερα αναφέρεται και ως μία από τις μεθόδους της εποπτευόμενης μάθησης (supervised learning) στον τομέα της στατιστικής μηχανικής μάθησης. Συγκεκριμένα, για τη δημιουργία του μοντέλου πρόβλεψης του ύψους των ασφαλιστικών απαιτήσεων, εφαρμόστηκαν και συγκρίθηκαν ως προς την ακρίβειά τους πέντε δημοφιλείς αλγόριθμοι ανάλυσης παλινδρόμησης: 1) Η Πολλαπλή Γραμμική Παλινδρόμηση (Linear Regression), 2) Η Παλινδρόμηση LASSO (LASSO Regression), 3) Η Παλινδρόμηση με k πλησιέστερους γείτονες (k-Neighbors Regression), 4) Η Παλινδρόμηση με Τυχαία Δάση (Random Forest Regression) και 5) Η Παλινδρόμηση με την τεχνική ενίσχυσης κλίσης (Gradient Boosting Regression).
Στο πλαίσιο της επιλογής του κατάλληλου μοντέλου, το αρχικό σύνολο δεδομένων χωρίστηκε σε δύο κατηγορίες: στα δεδομένα εκπαίδευσης και στα δεδομένα δοκιμής. Το σύνολο δεδομένων εκπαίδευσης (training data set) περιέχει το 80% των παρατηρήσεων και χρησιμοποιείται στην εκπαίδευση του μοντέλου, ενώ το σύνολο δεδομένων δοκιμής (test data) ?περιέχει το 20% των παρατηρήσεων και χρησιμποιείται στο στάδιο της πρόβλεψης. Στη συνέχεια, για την αξιολόγηση και σύγκριση των μοντέλων χρησιμοποιήθηκε η τεχνική της διασταυρούμενης επικύρωσης 10 τμημάτων (Cross Validaton 10-Fold), λαμβάνοντας υπόψη τις παρακάτω μετρικές:
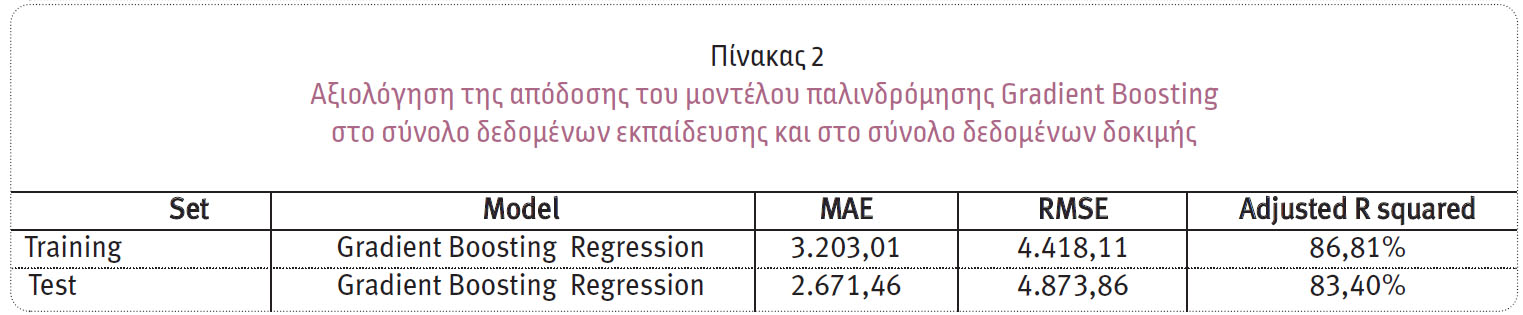
Στον Πίνακα 1 παρουσιάζονται τα αποτελέσματα της αξιολόγησης των μοντέλων με χρήση της διασταυρούμενης επικύρωσης για το μέσο απόλυτο σφάλμα, το μέσο τετραγωνικό σφάλμα και τον προσαρμοσμένο συντελεστή προσδιορισμού, σε κάθε μοντέλο παλινδρόμησης. Όσο πιο μικρές είναι οι τιμές των σφαλμάτων, τόσο καλύτερη είναι η προσαρμογή του μοντέλου παλινδρόμησης. Σύμφωνα με τα παραπάνω κριτήρια, βέλτιστο μοντέλο κρίθηκε το μοντέλο παλινδρόμησης που χρησιμοποιεί την τεχνική Gradient Boosting Regression, το οποίο φαίνεται να έχει μικρότερο σφάλμα (MAE=3.867,33 & RMSE=5.233,55) και υψηλότερη ερμηνευτική ικανότητα (R2=80,78%) από τα υπόλοιπα μοντέλα παλινδρόμησης. Ο αλγόριθμος παλινδρόμησης Gradient Boosting είναι μία τεχνική που βασίζεται σε δέντρα αποφάσεων, στην οποία κάθε δέντρο εκπαιδεύεται χρησιμοποιώντας την πληροφορία από τα προηγούμενα δέντρα, με στόχο να συνδυαστούν για την κατασκευή ενός ισχυρότερου μοντέλου. Ο αλγόριθμος Gradient Boosting βασίζεται σε ένα σύνολο παραμέτρων, οι οποίες μπορούν να βελτιστοποιηθούν και να δώσουν βέλτιστες ιδιότητες στο τελικό μοντέλο. Για τη συγκεκριμένη εφαρμογή και ύστερα από τη διαδικασία της βελτιστοποίησης των παραμέτρων, προέκυψε το τελικό μοντέλο, τα μέσα απόδοσης του οποίου παρατίθενται στον Πίνακα 2.
Όπως φαίνεται και στον Πίνακα 2, η ερμηνευτική δυνατότητα του μοντέλου στο σύνολο δεδομένων εκπαίδευσης είναι ίση με 86,81% και στο σύνολο δεδομένων δοκιμής είναι ίση με 83,40%, βάσει του προσαρμοσμένου συντελεστή προσδιορισμού. Αυτό σημαίνει ότι ανεξάρτητες μεταβλητές του μοντέλου ερμηνεύουν το 83,40% της μεταβλητότητας της μεταβλητής που αφορά το ύψος των ασφαλιστικών απαιτήσεων.
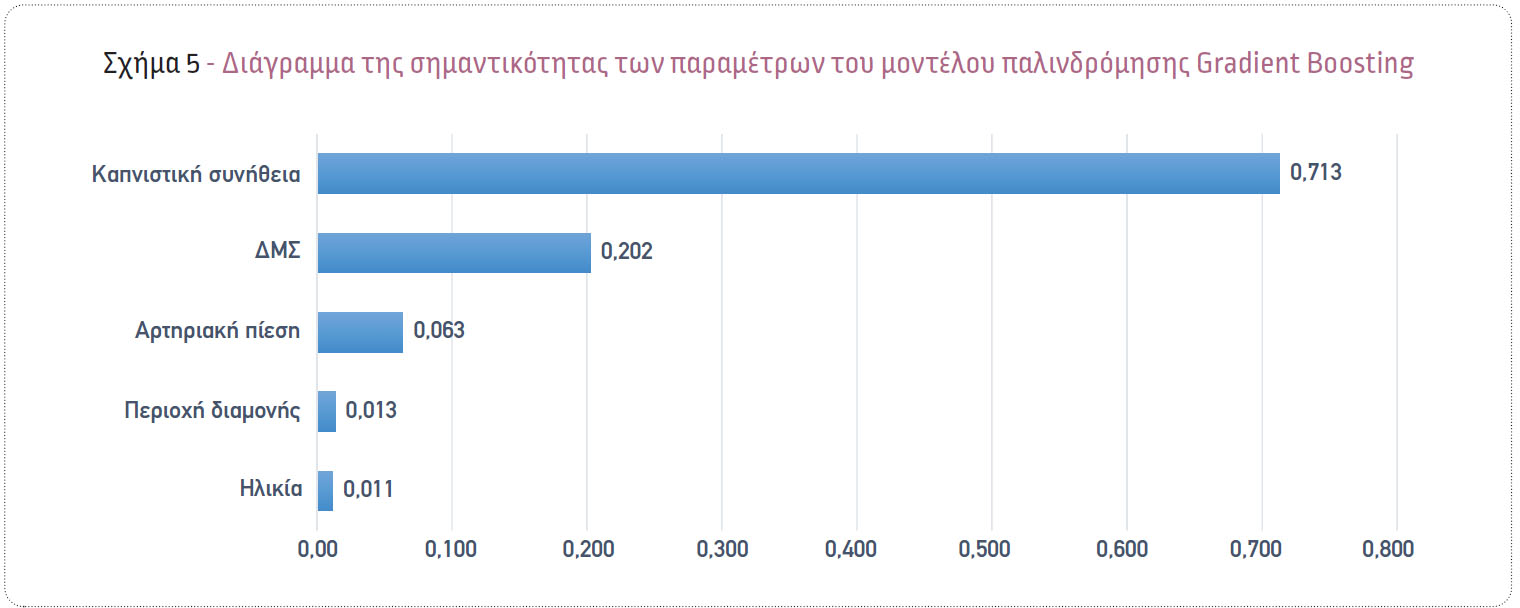
Στο τελικό μοντέλο, δεν χρησιμοποιήθηκαν όλες οι διαθέσιμες παράμετροι (μεταβλητές). Οι μεταβλητές που χρησιμοποιήθηκαν είναι εκείνες που αποδείχθηκαν ισχυροί προγνωστικοί παράγοντες και είναι η καπνιστική συνήθεια, ο δείκτης μάζας σώματος (ΔΜΣ), η αρτηριακή πίεση, η περιοχή διαμονής και η ηλικία των αιτούντων ασφαλιστικής αποζημίωσης (Σχήμα 5).
Το προγνωστικό μοντέλο θα είναι άρρηκτα συνδεδεμένο με τη διαχείριση του κινδύνου της ασφαλιστικής εταιρείας και με τη βοήθειά του η εταιρεία μπορεί να μειώσει το κόστος, να προβλέψει, όντας προετοιμασμένη, για μελλοντικές αξιώσεις, καθώς και να ανακαλύψει πρότυπα τα οποία μπορεί να οδηγήσουν στην αναπροσαρμογή της τιμολογιακής της πολιτικής. Συγκεκριμένα, η ασφαλιστική εταιρεία, γνωρίζοντας το μείγμα των ασφαλισμένων και τα χαρακτηριστικά τους, τα οποία τα αντλεί από το αίτημα συμβολαίου, μπορεί να υπολογίσει με μεγάλη ακρίβεια το ύψος των μελλοντικών ασφαλιστικών απαιτήσεων, καθώς και να ενδυναμώσει την ακρίβεια της διαδικασίας αξιολόγησης της επικινδυνότητας των ασφαλισμένων. Επίσης, με περαιτέρω ανάλυση, το προγνωστικό μοντέλο μπορεί να χρησιμοποιηθεί για δυναμική τιμολόγηση των ασφαλίστρων.
*Ο κ. Σωτήριος Μπερσίμης είναι Αναπληρωτής Καθηγητής στο Πανεπιστήμιο Πειραιώς.
*Ο κ. Χρήστος Μπουντούλης είναι επιστήμονας των Δεδομένων στην εταιρεία Covariance, με εξειδίκευση στον ασφαλιστικό κλάδο.
Διαβάστε επίσης:
Η αξιοποίηση των Big Data στον ασφαλιστικό κλάδο
Ανίχνευση ασφαλιστικής απάτης στην ασφάλιση κατοικίας
Ανίχνευση ασφαλιστικής απάτης στην ασφάλιση αυτοκινήτων
Πρόβλεψη πώλησης Ασφάλισης Οχήματος σε πελάτες με Ασφαλιστήρια Υγείας
Ασφάλιση αυτοκινήτου: Ποιοι πελάτες θα ανανεώσουν το ασφαλιστήριό τους;
Ακολουθήστε την Ασφαλιστική Αγορά στο Google News






